
|
| Aug '25 |
|
| May '25 |
|
| May '25 | Excited to present our new imitation learning framework called streaming flow policy at the Beyond Pick and Place Workshop at ICRA 2025! |
| Jan '25 | Our paper on anomaly detection using diffusion models for off-road navigation is accepted to ICRA 2025! |
| Jun '24 | Our paper on learning traversability for risk-aware navigation is accepted to the Transactions in Robotics (T-RO) 2024! |
| May '24 | Our paper on learning traversability priors using diffusion models for path planning is accepted to the ICRA 2024 Workshop on Resilient Off-road Autonomy as an Oral presentation! |
| Apr '24 | 🏆 Our paper on uncertainty estimation for semantic segmentation is nominated for the best paper award in the robot vision category at ICRA 2024! |
| Apr '23 | Our paper on velocity estimation using light curtains is accepted to RSS 2023! |
| Apr '23 | 🏆 Selected to Rising Stars in Cyber-Physical Systems at the University of Virginia in May 2023! |
| Sep '22 | 🏆 Honored to receive the IROS 2022 Outstanding Reviewer Award, awarded to 5 out of 4,291 reviewers! |
| Jul '22 | Successfully defended my PhD thesis! A big thanks to my thesis committee: David Held, Srinivasa Narasimhan, Katerina Fragkiadaki and Wolfram Burgard. Also thanks to Chris Atkeson for the many insightful and interesting questions! |
| Feb '22 | Excited to join Nick Roy's Robust Robotics Group at MIT as a postdoc this August! |
| Dec '21 | Proposed my PhD thesis titled Active robot perception using programmable light curtains. Expected to defend and graduate in July 2022. Thesis committee: David Held, Srinivasa Narasimhan, Katerina Fragkiadaki and Wolfram Burgard. |
| Nov '21 | Published a CMU ML Blog Post on our recent work on safety envelopes using light curtains, presented at RSS '21. Check it out! |

|
University of California, Berkeley Research Scientist 2025 ─ Present |

|
Massachusetts Institute of Technology Postdoctoral Associate / Research Scientist Computer Science & Artificial Intelligence Lab (CSAIL) 2022 ─ 2025 |

|
Carnegie Mellon University PhD, Machine Learning Department School of Computer Science (SCS) 2017 ─ 2022 |

|
University of Toronto MS in Computer Science Department of Computer Science (DCS) 2015 ─ 2017 |

|
Indian Institute of Technology, Guwahati BTech Major in Computer Science & Engineering BTech Minor in Mathematics 2011 ─ 2015 |
|
webpage |
abstract |
pdf |
bibtex |
talk |
code
Simulation is an indispensable tool for evaluating robot algorithms in a safe and scalable manner. However, current simulation benchmarks introduce an artificial sim-to-real gap by running robot policies *synchronously*, i.e., pausing the simulation to let the policy "think” for as long as it needs before executing actions. But real world physics does not wait for policy inference. Synchronous evaluation provides an unfair advantage to heavyweight policies with large backbones or iterative denoising that may be performant, but are too slow in the real world. We introduce |
|
@inproceedings{song2026asyncrobosim,
title = {Simulation for evaluating robot policies should be asynchronous and real-time},
author = {Python Song AND Hyeonho Oh AND Ishika Singh AND Jesse Thomason AND Ajay Mandlekar AND Siddharth Ancha},
year = {2026},
url = {https://anonymous.4open.science/r/realtime-robosuite}
}
|
|
|
webpage |
abstract |
pdf |
bibtex |
talk |
twitter |
code |
notebooks
Recent advances in diffusion/flow-matching policies have enabled imitation learning of complex, multi-modal action trajectories. However, they are computationally expensive because they sample a trajectory of trajectories — a diffusion/flow trajectory of action trajectories. They discard intermediate action trajectories, and must wait for the sampling process to complete before any actions can be executed on the robot. We simplify diffusion/flow policies by treating action trajectories as flow trajectories. Instead of starting from pure noise, our algorithm samples from a narrow Gaussian around the last action. Then, it incrementally integrates a velocity field learned via flow matching to produce a sequence of actions that constitute a single trajectory. This enables actions to be streamed to the robot on-the-fly during the flow sampling process, and is well-suited for receding horizon policy execution. Despite streaming, our method retains the ability to model multi-modal behavior. We train flows that stabilize around demonstration trajectories to reduce distribution shift and improve imitation learning performance. Streaming flow policy outperforms prior methods while enabling faster policy execution and tighter sensorimotor loops for learning-based robot control. |
|
@inproceedings{jiang2025streaming,
title = {Streaming Flow Policy: Simplifying diffusion/flow-matching policies by treating action trajectories as flow trajectories},
author = {Sunshine Jiang AND Xiaolin Fang AND Nicholas Roy AND Tom{\'a}s Lozano-P{\'e}rez AND Leslie Pack Kaelbling AND Siddharth Ancha},
booktitle = {9th Annual Conference on Robot Learning, CoRL 2025},
year = {2025},
address = {Seoul, Korea},
month = {September},
url = {https://openreview.net/forum?id=jnpILGz9gQ}
}
|
|

|
webpage |
abstract |
pdf |
bibtex |
talk |
code |
twitter |
colab
In order to navigate safely and reliably in off-road and unstructured environments, robots must detect anomalies that are out-of-distribution (OOD) with respect to the training data. We present an analysis-by-synthesis approach for pixel-wise anomaly detection without making any assumptions about the nature of OOD data. Given an input image, we use a generative diffusion model to synthesize an edited image that removes anomalies while keeping the remaining image unchanged. Then, we formulate anomaly detection as analyzing which image segments were modified by the diffusion model. We propose a novel inference approach for guided diffusion by analyzing the ideal guidance gradient and deriving a principled approximation that bootstraps the diffusion model to predict guidance gradients. Our editing technique is purely test-time that can be integrated into existing workflows without the need for retraining or fine-tuning. Finally, we use a combination of vision-language foundation models to compare pixels in a learned feature space and detect semantically meaningful edits, enabling accurate anomaly detection for off-road navigation. |
@inproceedings{jiang2025icra,
title = {Anomalies by Synthesis: Anomaly Detection using Generative Diffusion Models for Off-Road Navigation},
author = {Sunshine Jiang AND Siddharth Ancha AND Travis Manderson AND Laura Brandt AND Yilun Du AND Philip R. Osteen AND Nicholas Roy},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2025},
address = {Atlanta, USA},
month = {May},
}
|
|

|
abstract |
pdf |
bibtex
Robots have limited sensor ranges, restricting what they can observe, complicating navigation through a-priori unknown environments. If environment structure is present, priors over this structure can extend the utility of local observations and improve navigation performance. In this work, we propose learning priors over the semantic structure of navigation environments using state-of-the-art generative diffusion models. We show that diffusion models can capture complex spatial dependencies in overhead semantic maps, and are able to infer the semantics of far-away unobserved regions conditioned on local semantics already observed by the robot. By sampling a diverse, multi-modal set of high-fidelity semantic maps that are consistent with observed regions, we are able to estimate far-field navigation costs in an uncertainty-aware manner. Our preliminary investigations suggest that diffusion-based uncertainty-aware navigation costs can enable a downstream global planner to find more efficient paths and improve navigation performance. |
@inproceedings{fahnestock2024traversability,
title = {Learning semantic traversability priors using diffusion models for uncertainty-aware global path planning},
author = {Ethan Fahnestock AND Erick Fuentes AND Philip R. Osteen AND Siddharth Ancha AND Nicholas Roy},
booktitle = {ICRA Workshop on Resilient Off-road Autonomy},
year = {2024},
}
|
|
|
webpage |
abstract |
pdf |
bibtex |
talk |
code
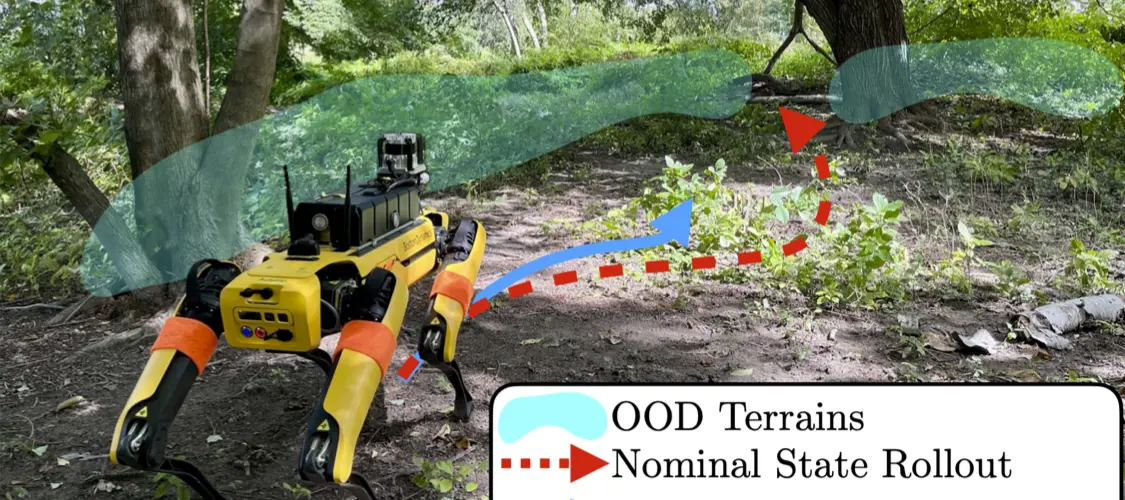
Traversing terrain with good traction is crucial for achieving fast off-road navigation. Instead of manually designing costs based on terrain features, existing methods learn terrain properties directly from data via self-supervision, but challenges remain to properly quantify and mitigate risks due to uncertainties in learned models. This work efficiently quantifies both aleatoric and epistemic uncertainties by learning discrete traction distributions and probability densities of the traction predictor's latent features. Leveraging evidential deep learning, we parameterize Dirichlet distributions with the network outputs and propose a novel uncertainty-aware squared Earth Mover's distance loss with a closed-form expression that improves learning accuracy and navigation performance. The proposed risk-aware planner simulates state trajectories with the worst-case expected traction to handle aleatoric uncertainty, and penalizes trajectories moving through terrain with high epistemic uncertainty. Our approach is extensively validated in simulation and on wheeled and quadruped robots, showing improved navigation performance compared to methods that assume no slip, assume the expected traction, or optimize for the worst-case expected cost. |
@inproceedings{cai2023evora,
title = {EVORA: Deep EVidential Traversability Learning for Risk-Aware Off-Road Autonomy},
author = {Xiaoyi Cai AND Siddharth Ancha AND Lakshay Sharma AND Philip R. Osteen AND Bernadette Bucher AND Stephen Phillips AND Jiuguang Wang AND Michael Everett AND Nicholas Roy AND Jonathan P. How},
booktitle = {arXiv preprint arXiv:2311.06234},
year = {2023},
}
|
|

|
webpage |
abstract |
pdf |
bibtex |
talk
In order to navigate safely and reliably in novel environments, robots must estimate perceptual uncertainty when confronted with out-of-distribution (OOD) obstacles not seen in training data. We present a method to accurately estimate pixel-wise uncertainty in semantic segmentation without requiring real or synthetic OOD examples at training time. From a shared per-pixel latent feature representation, a classification network predicts a categorical distribution over semantic labels, while a normalizing flow estimates the probability density of features under the training distribution. The label distribution and density estimates are combined in a Dirichlet-based evidential uncertainty framework that efficiently computes epistemic and aleatoric uncertainty in a single neural network forward pass. Our method is enabled by three key contributions. First, we simplify the problem of learning a transformation to the training data density by starting from a fitted Gaussian mixture model instead of the conventional standard normal distribution. Second, we learn a richer and more expressive latent pixel representation to aid OOD detection by training a decoder to reconstruct input image patches. Third, we perform theoretical analysis of the loss function used in the evidential uncertainty framework and propose a principled objective that more accurately balances training the classification and density estimation networks. We demonstrate the accuracy of our uncertainty estimation approach under long-tail OOD obstacle classes for semantic segmentation in both off-road and urban driving environments. |
@inproceedings{ancha2024icra,
title = {Deep Evidential Uncertainty Estimation for Semantic Segmentation under Out-Of-Distribution Obstacles},
author = {Siddharth Ancha AND Philip R. Osteen AND Nicholas Roy},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2024},
address = {Yokohama, Japan},
month = {May},
}
|
|

|
webpage |
abstract |
pdf |
bibtex |
talk
As factories continue to evolve into collaborative spaces with multiple robots working together with human supervisors in the loop, ensuring safety for all actors involved becomes critical. Currently, laser-based light curtain sensors are widely used in factories for safety monitoring. While these conventional safety sensors meet high accuracy standards, they are difficult to reconfigure and can only monitor a fixed user-defined region of space. Furthermore, they are typically expensive. Instead, we leverage a controllable depth sensor, programmable light curtains, to develop an inexpensive and flexible real-time safety monitoring system for collaborative robot workspaces. Our system projects virtual dynamic safety envelopes that tightly envelop the moving robot at all times and detect any objects that intrude the envelope. Furthermore, we develop an instrumentation algorithm that optimally places (multiple) light curtains in a workspace to maximize the visibility coverage of robots. Our work enables fence-less human-robot collaboration, while scaling to monitor multiple robots with few sensors. We analyze our system in a real manufacturing testbed with four robot arms and demonstrate its capabilities as a fast, accurate, and inexpensive safety monitoring solution. |
@article{ram2024robot,
title={Robot Safety Monitoring using Programmable Light Curtains},
author={Ram, Karnik and Aggarwal, Shobhit and Tamburo, Robert and Ancha, Siddharth and Narasimhan, Srinivasa},
journal={arXiv preprint arXiv:2404.03556},
year={2024}
}
|
|
|
webpage |
abstract |
pdf |
bibtex |
code |
short talk |
long talk
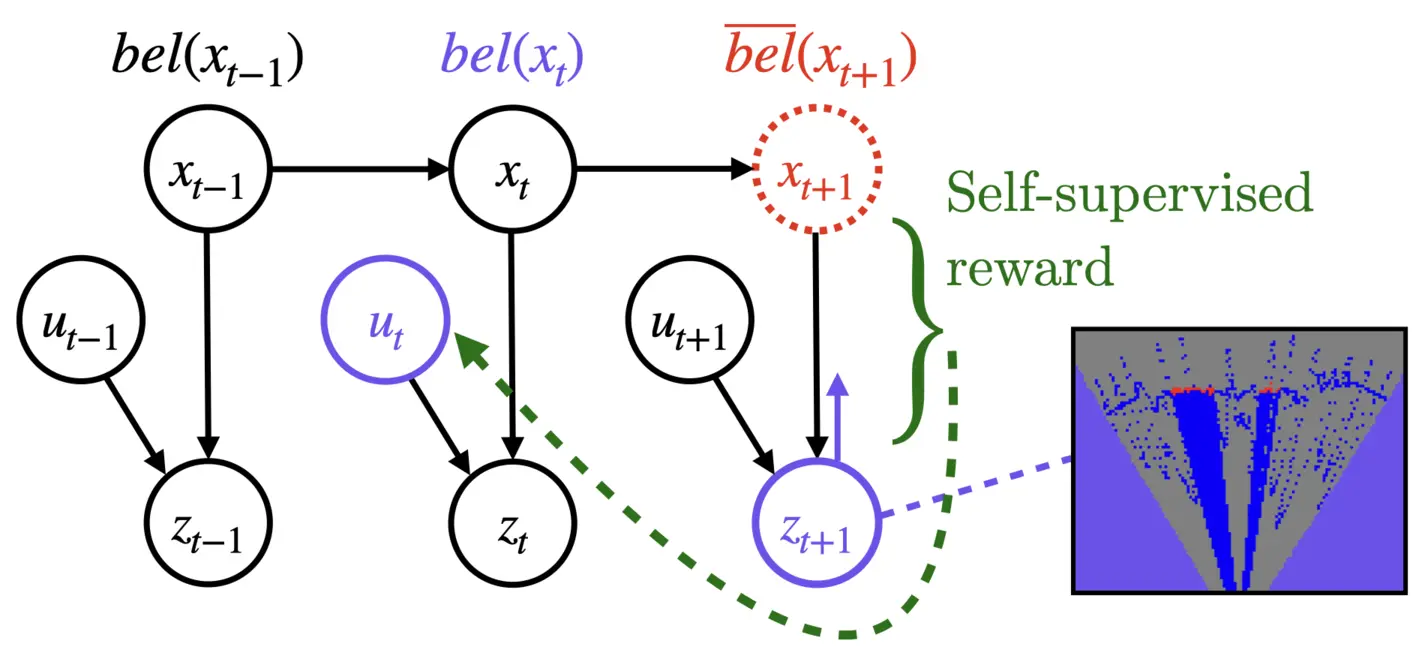
To navigate in an environment safely and autonomously, robots must accurately estimate where obstacles are and how they move. Instead of using expensive traditional 3D sensors, we explore the use of a much cheaper, faster, and higher resolution alternative: programmable light curtains. Light curtains are a controllable depth sensor that sense only along a surface that the user selects. We adapt a probabilistic method based on particle filters and occupancy grids to explicitly estimate the position and velocity of 3D points in the scene using partial measurements made by light curtains. The central challenge is to decide where to place the light curtain to accurately perform this task. We propose multiple curtain placement strategies guided by maximizing information gain and verifying predicted object locations. Then, we combine these strategies using an online learning framework. We propose a novel self-supervised reward function that evaluates the accuracy of current velocity estimates using future light curtain placements. We use a multi-armed bandit framework to intelligently switch between placement policies in real time, outperforming fixed policies. We develop a full-stack navigation system that uses position and velocity estimates from light curtains for downstream tasks such as localization, mapping, path-planning, and obstacle avoidance. This work paves the way for controllable light curtains to accurately, efficiently, and purposefully perceive and navigate complex and dynamic environments. |
@inproceedings{ancha2023rss,
title = {Active Velocity Estimation using Light Curtains via Self-Supervised Multi-Armed Bandits},
author = {Siddharth Ancha AND Gaurav Pathak AND Ji Zhang AND Srinivasa Narasimhan AND David Held},
booktitle = {Proceedings of Robotics: Science and Systems},
year = {2023},
address = {Daegu, Republic of Korea},
month = {July},
}
|
|
 |
webpage |
abstract |
pdf |
bibtex |
code |
short talk |
long talk |
slides
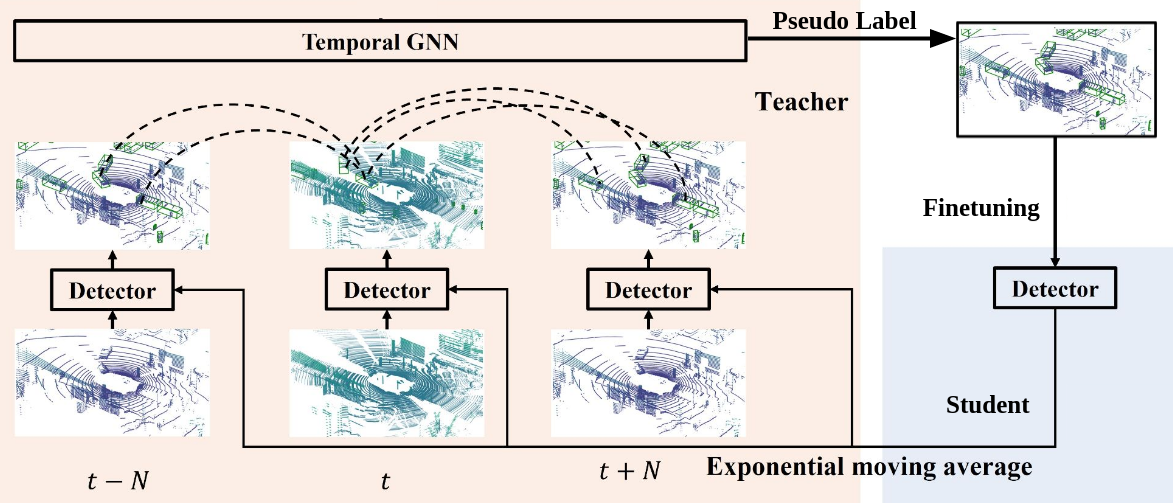
3D object detection plays an important role in autonomous driving and other robotics applications. However, these detectors usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging large amounts of unlabeled point cloud videos by semi-supervised learning of 3D object detectors via temporal graph neural networks. Our insight is that temporal smoothing can create more accurate detection results on unlabeled data, and these smoothed detections can then be used to retrain the detector. We learn to perform this temporal reasoning with a graph neural network, where edges represent the relationship between candidate detections in different time frames. After semi-supervised learning, our method achieves state-of-the-art detection performance on the challenging nuScenes and H3D benchmarks, compared to baselines trained on the same amount of labeled data. |
@inproceedings{jianren21sod-tgnn,
author = {Jianren Wang AND Haiming Gang AND Siddarth Ancha AND Yi-Ting Cheng AND David Held},
title = {Semi-supervised 3D Object Detection via Temporal Graph Neural Networks},
booktitle = {3DV},
year = {2021}
}
|
|
|
webpage |
abstract |
pdf |
bibtex |
code |
talk |
blog |
twitter
To safely navigate unknown environments, robots must accurately perceive dynamic obstacles. Instead of directly measuring the scene depth with a LiDAR sensor, we explore the use of a much cheaper and higher resolution sensor: programmable light curtains. Light curtains are controllable depth sensors that sense only along a surface that a user selects. We use light curtains to estimate the safety envelope of a scene: a hypothetical surface that separates the robot from all obstacles. We show that generating light curtains that sense random locations (from a particular distribution) can quickly discover the safety envelope for scenes with unknown objects. Importantly, we produce theoretical safety guarantees on the probability of detecting an obstacle using random curtains. We combine random curtains with a machine learning based model that forecasts and tracks the motion of the safety envelope efficiently. Our method accurately estimates safety envelopes while providing probabilistic safety guarantees that can be used to certify the efficacy of a robot perception system to detect and avoid dynamic obstacles. We evaluate our approach in a simulated urban driving environment and a real-world environment with moving pedestrians using a light curtain device and show that we can estimate safety envelopes efficiently and effectively. |
|
@inproceedings{Ancha-RSS-21,
author = {Siddharth Ancha AND Gaurav Pathak AND Srinivasa Narasimhan AND David Held},
title = {Active Safety Envelopes using Light Curtains with Probabilistic Guarantees},
booktitle = {Proceedings of Robotics: Science and Systems},
year = {2021},
address = {Virtual},
month = {July},
doi = {10.15607/rss.2021.xvii.045}
}
|
|
 |
webpage |
abstract |
pdf |
bibtex |
code |
talk
Active sensing through the use of adaptive depth sensors is a nascent field, with potential in areas such as advanced driver-assistance systems (ADAS). They do however require dynamically driving a laser / light-source to a specific location to capture information, with one such class of sensors being programmable light curtains. In this work, we introduce a novel approach that exploits prior depth distributions from RGB cameras to drive a light curtain's laser line to regions of uncertainty to get new measurements. These measurements are utilized such that depth uncertainty is reduced and errors get corrected recursively. We show real-world experiments that validate our approach in outdoor and driving settings, and demonstrate qualitative and quantitative improvements in depth RMSE when RGB cameras are used in tandem with a light curtain. |
@inproceedings{cvpr2021raajexploiting,
author = {Yaadhav Raaj AND Siddharth Ancha AND Robert Tamburo AND David Held, Srinivasa Narasimhan},
title = {Exploiting and Refining Depth Distributions with Triangulation Light Curtains},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}
|
|
 |
webpage |
abstract |
pdf |
bibtex |
code |
short talk |
long talk |
slides
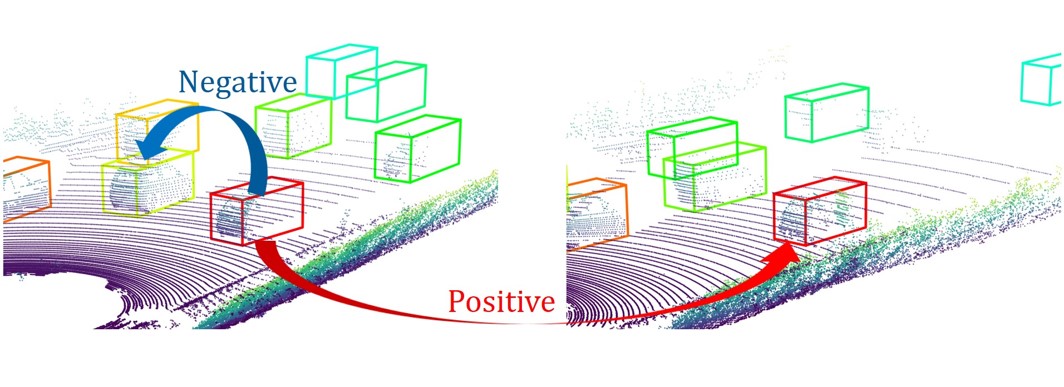
Most real-world 3D sensors such as LiDARs perform fixed scans of the entire environment, while being decoupled from the recognition system that processes the sensor data. In this work, we propose a method for 3D object recognition using light curtains, a resource-efficient controllable sensor that measures depth at user-specified locations in the environment. Crucially, we propose using prediction uncertainty of a deep learning based 3D point cloud detector to guide active perception. Given a neural network's uncertainty, we derive an optimization objective to place light curtains using the principle of maximizing information gain. Then, we develop a novel and efficient optimization algorithm to maximize this objective by encoding the physical constraints of the device into a constraint graph and optimizing with dynamic programming. We show how a 3D detector can be trained to detect objects in a scene by sequentially placing uncertainty-guided light curtains to successively improve detection accuracy. |
@inproceedings{ancha2020eccv,
author = {Ancha, Siddharth AND Raaj, Yaadhav AND Hu, Peiyun AND Narasimhan Srinivasa G. AND Held, David},
editor = {Vedaldi, Andrea AND Bischof, Horst AND Brox, Thomas AND Frahm, Jan-Michael},
title = {Active Perception Using Light Curtains for Autonomous Driving},
booktitle = {Computer Vision -- ECCV 2020},
year = {2020},
publisher = {Springer International Publishing},
address = {Cham},
pages = {751--766},
isbn = {978-3-030-58558-7}
}
|
|
 |
webpage |
abstract |
pdf |
bibtex |
talk |
slides |
code
3D object trackers usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging vast unlabeled datasets by self-supervised metric learning of 3D object trackers, with a focus on data association. Large scale annotations for unlabeled data are cheaply obtained by automatic object detection and association across frames. We show how these self-supervised annotations can be used in a principled manner to learn point-cloud embeddings that are effective for 3D tracking. We estimate and incorporate uncertainty in self-supervised tracking to learn more robust embeddings, without needing any labeled data. We design embeddings to differentiate objects across frames, and learn them using uncertainty-aware self-supervised training. Finally, we demonstrate their ability to perform accurate data association across frames, towards effective and accurate 3D tracking. |
@inproceedings{jianren20s3da,
author = {Wang, Jianren AND Ancha, Siddharth AND Chen, Yi-Ting AND Held, David},
title = {Uncertainty-aware Self-supervised 3D Data Association},
booktitle = {IROS},
year = {2020}
}
|
|
 |
webpage |
abstract |
pdf |
bibtex |
talk |
code
Deep learning object detectors often return false positives with very high confidence. Although they optimize generic detection performance, such as mean average precision (mAP), they are not designed for reliability. For a reliable detection system, if a high confidence detection is made, we would want high certainty that the object has indeed been detected. To achieve this, we have developed a set of verification tests which a proposed detection must pass to be accepted. We develop a theoretical framework which proves that, under certain assumptions, our verification tests will not accept any false positives. Based on an approximation to this framework, we present a practical detection system that can verify, with high precision, whether each detection of a machine-learning based object detector is correct. We show that these tests can improve the overall accuracy of a base detector and that accepted examples are highly likely to be correct. This allows the detector to operate in a high precision regime and can thus be used for robotic perception systems as a reliable instance detection method. |
@inproceedings{FlowVerify2019CoRL,
author = {Siddharth Ancha AND Junyu Nan AND David Held},
editor = {Leslie Pack Kaelbling AND Danica Kragic AND Komei Sugiura},
title = {Combining Deep Learning AND Verification for Precise Object Instance Detection},
booktitle = {3rd Annual Conference on Robot Learning, CoRL 2019, Osaka, Japan, October 30 - November 1, 2019, Proceedings},
series = {Proceedings of Machine Learning Research},
volume = {100},
pages = {122--141},
year = {2019},
url = {https://proceedings.mlr.press/v100/ancha20a.html},
timestamp = {Mon, 25 May 2020 15:01:26 +0200},
biburl = {https://dblp.org/rec/conf/corl/AnchaNH19.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
|
|
 |
abstract |
pdf |
bibtex |
code
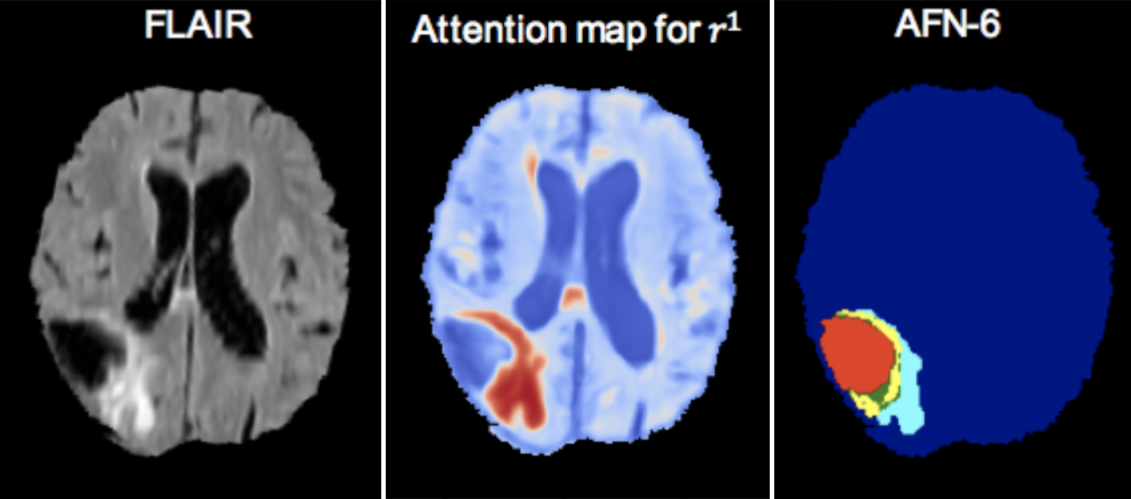
We propose the autofocus convolutional layer for semantic segmentation with the objective of enhancing the capabilities of neural networks for multi-scale processing. Autofocus layers adaptively change the size of the effective receptive field based on the processed context to generate more powerful features. This is achieved by parallelising multiple convolutional layers with different dilation rates, combined with an attention mechanism that learns to focus on the optimal scales driven by context. By sharing the weights of parallel convolutions, we make the network scale-invariant, with only a modest increase in the number of parameters. The proposed autofocus layer can be easily integrated into existing networks to improve the model's representational power. Our method achieves very promising performance on the challenging tasks of multi-organ segmentation in pelvic CT scans and brain tumor segmentation in MRI scans. |
@inproceedings{qin2018autofocus,
title = {Autofocus layer for semantic segmentation},
author = {Qin, Yao AND Kamnitsas, Konstantinos AND Ancha, Siddharth AND Nanavati, Jay AND Cottrell, Garrison AND Criminisi, Antonio AND Nori, Aditya},
booktitle = {International conference on medical image computing and computer-assisted intervention (MICCAI)},
pages = {603--611},
year = {2018},
organization = {Springer}
}
|
|
 |
abstract |
pdf |
bibtex
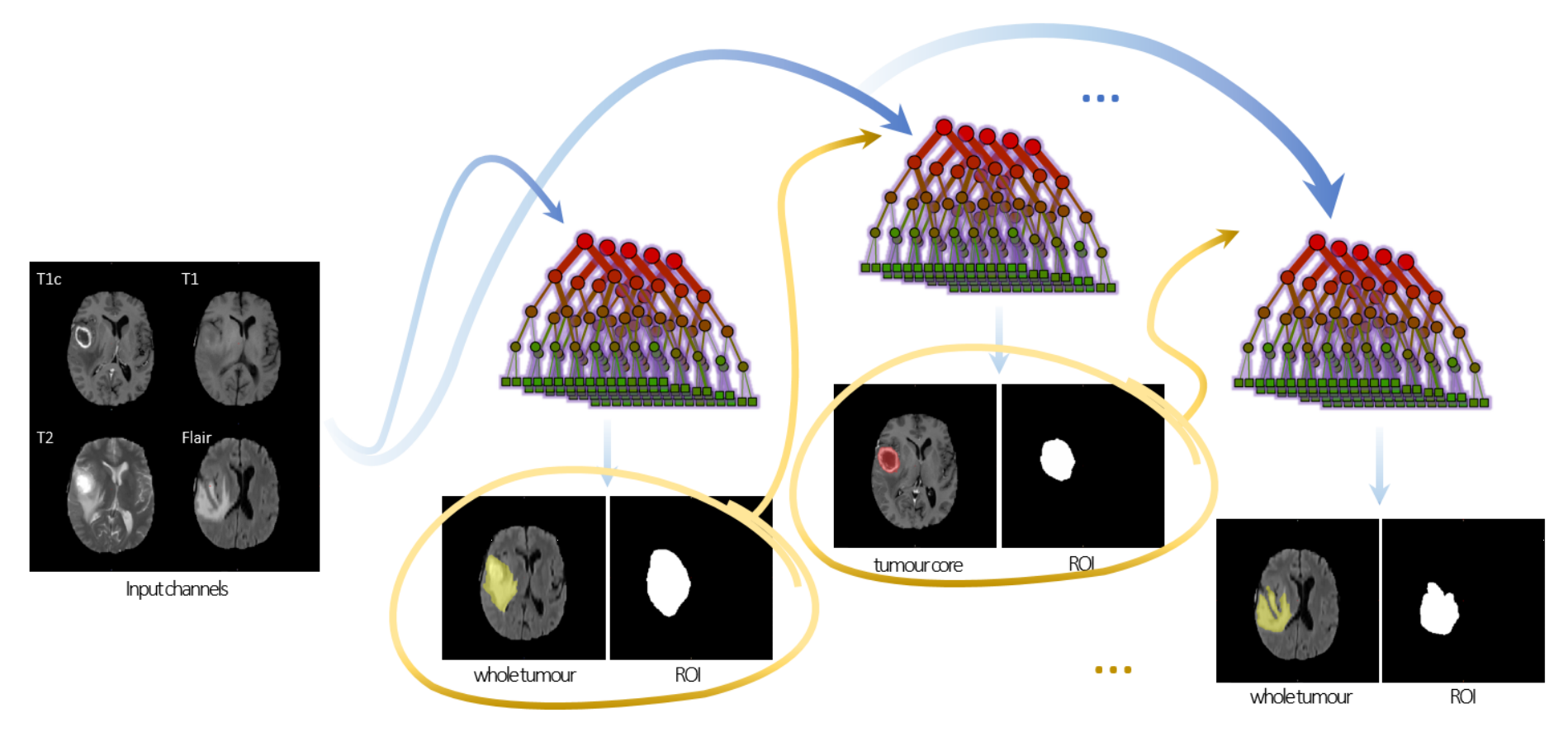
We revisit Auto-Context Forests for brain tumour segmentation in multi-channel magnetic resonance images, where semantic context is progressively built and refined via successive layers of Decision Forests (DFs). Specifically, we make the following contributions: (1) improved generalization via an efficient node-splitting criterion based on hold-out estimates, (2) increased compactness at the tree level, thereby yielding shallow discriminative ensembles trained orders of magnitude faster, and (3) guided semantic bagging that exposes latent data-space semantics captured by forest pathways. The proposed framework is practical: the per-layer training is fast, modular and robust. It was a top performer in the MICCAI 2016 BraTS (Brain Tumour Segmentation) challenge, and this paper aims to discuss and provide details about the challenge entry. |
@inproceedings{le2016lifted,
title = {Lifted auto-context forests for brain tumour segmentation},
author = {Le Folgoc, Loic AND Nori, Aditya V AND Ancha, Siddharth AND Criminisi, Antonio},
booktitle = {International Workshop on Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries},
pages = {171--183},
year = {2016},
organization= {Springer}
}
|
|
 |
abstract |
pdf |
bibtex |
code
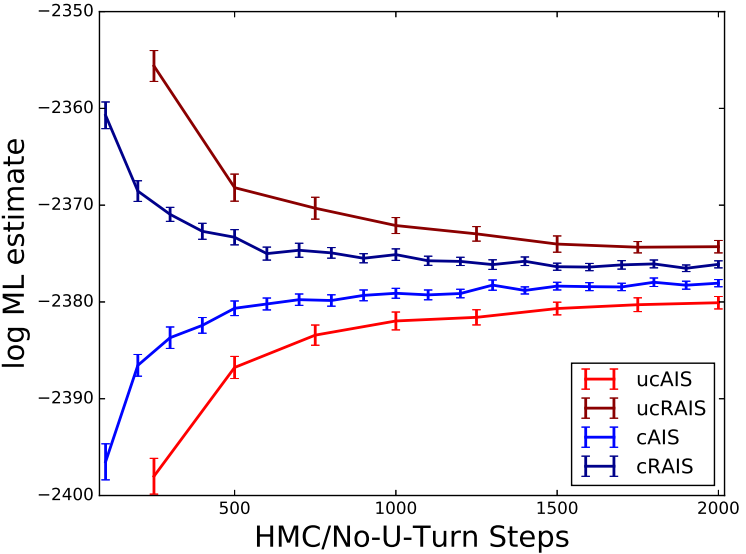
Markov chain Monte Carlo (MCMC) is one of the main workhorses of probabilistic inference, but it is notoriously hard to measure the quality of approximate posterior samples. This challenge is particularly salient in black box inference methods, which can hide details and obscure inference failures. In this work, we extend the recently introduced bidirectional Monte Carlo technique to evaluate MCMC-based posterior inference algorithms. By running annealed importance sampling (AIS) chains both from prior to posterior and vice versa on simulated data, we upper bound in expectation the symmetrized KL divergence between the true posterior distribution and the distribution of approximate samples. We present Bounding Divergences with REverse Annealing (BREAD), a protocol for validating the relevance of simulated data experiments to real datasets, and integrate it into two probabilistic programming languages: WebPPL and Stan. As an example of how BREAD can be used to guide the design of inference algorithms, we apply it to study the effectiveness of different model representations in both WebPPL and Stan. |
@inproceedings{NIPS2016_0e9fa1f3,
author = {Grosse, Roger B AND Ancha, Siddharth AND Roy, Daniel M},
booktitle = {Advances in Neural Information Processing Systems},
editor = {D. Lee AND M. Sugiyama AND U. Luxburg AND I. Guyon AND R. Garnett},
publisher = {Curran Associates, Inc.},
title = {Measuring the reliability of MCMC inference with bidirectional Monte Carlo},
url = {https://proceedings.neurips.cc/paper/2016/file/0e9fa1f3e9e66792401a6972d477dcc3-Paper.pdf},
volume = {29},
year = {2016}
}
|
|
Template modified from this |